
Claude Fable 5登場——「Mythosクラス」は税務・法務・会計の実務をどこまで変えるか

ITPS Blog | 2026年6月10日
はじめに
2026年6月9日、AnthropicはClaude Fable 5を一般公開した[^1]。同社が「Mythosクラス」と呼ぶ、従来の最上位Opusのさらに上位に位置する新たなティアとなるモデルであり、一般ユーザーが利用できるものとしては同社史上最も高性能なモデルである。本稿では、Fable 5の位置づけ、従来モデルとの使い分け、新たに導入された「エフォートレベル」の考え方を整理したうえで、法務・税務の実務家として特に注目すべきLegal Agent Benchmark(LAB)の結果を読み解く。
1. Fable 5とは何か——MythosクラスとOpus/Sonnetの関係
Anthropicのモデルラインナップは従来、Opus(最上位)、Sonnet(中位)、Haiku(軽量)の三層構成だった。Fable 5はその上に新設されたMythosクラスの最初の一般公開モデルである。同時に発表されたClaude Mythos 5は同一の基盤モデルだが、サイバーセキュリティ等の分野のセーフガードを解除した版であり、米国政府と連携するProject Glasswingの限定パートナーにのみ提供される[^1]。
Fable 5の特徴は次の三点に集約される。
第一に、長期・自律タスクへの適性。 Anthropicは、タスクが長く複雑になるほど従来モデルとの差が開くと説明しており、早期テストではStripe社が5,000万行規模のコードベースで、人手なら一チームで2か月超を要する移行作業を1日で完了したと報告している[^1]。コーディングに限らず、数時間〜数週間規模の知的業務をエンドツーエンドで処理する設計である。
第二に、安全対策による「フォールバック」構造。 サイバーセキュリティ、生物・化学、蒸留(モデル能力の抽出)に関する質問は、分類器が検知して自動的にOpus 4.8が応答する仕組みになっている。Anthropicによれば、フォールバックが発生するセッションは全体の5%未満である[^1]。
第三に、価格と提供形態。 API価格は入力100万トークンあたり10ドル、出力50ドルで、Opus 4.8の約2倍に相当する。サブスクリプションプラン(Pro/Max/Team等)では2026年6月22日まで追加費用なしで利用でき、23日以降は当面、利用クレジットが必要となる[^1]。
使い分けの目安は単純で、「タスクの複雑性・長さ・手戻りコスト」が価格差を正当化するかどうかである。日常的な高度業務はOpus 4.8、軽量な反復作業やコスト重視の処理はSonnet 4.6、そして人間なら数日かかる検証・調査・開発をまとめて任せる場面でFable 5、という整理になる。
2. エフォートレベル——「どれだけ考えさせるか」という新しいダイヤル
Fable 5世代では、モデル選択に加えて「エフォート(effort)」が知性・速度・コストのトレードオフを調整する主要な制御手段となった[^2]。
| レベル | 想定用途 |
|---|---|
| xhigh | 長い探索・反復的なツール実行を伴う高度なコーディングや複雑なエージェント作業 |
| high(既定) | 複雑な推論、ニュアンスを要する分析など、速度・コストより品質を優先するタスク |
| medium | 品質と消費トークンのバランスを取りたい定常業務 |
| low | 単純な分類・確認・大量処理など、速度とコストを最優先する場面 |
興味深いのは、Fable 5では低めのエフォートでも従来モデルの最高設定を上回ることが多いとされる点である[^3]。つまり「最上位モデル×低エフォート」と「従来モデル×高エフォート」という選択肢が交差し、ユーザー側のタスク設計力が問われる時代になった。
3. ベンチマーク結果の読み解き
発表資料のベンチマーク表から、実務家の視点で注目すべき点を挙げる[^1]。
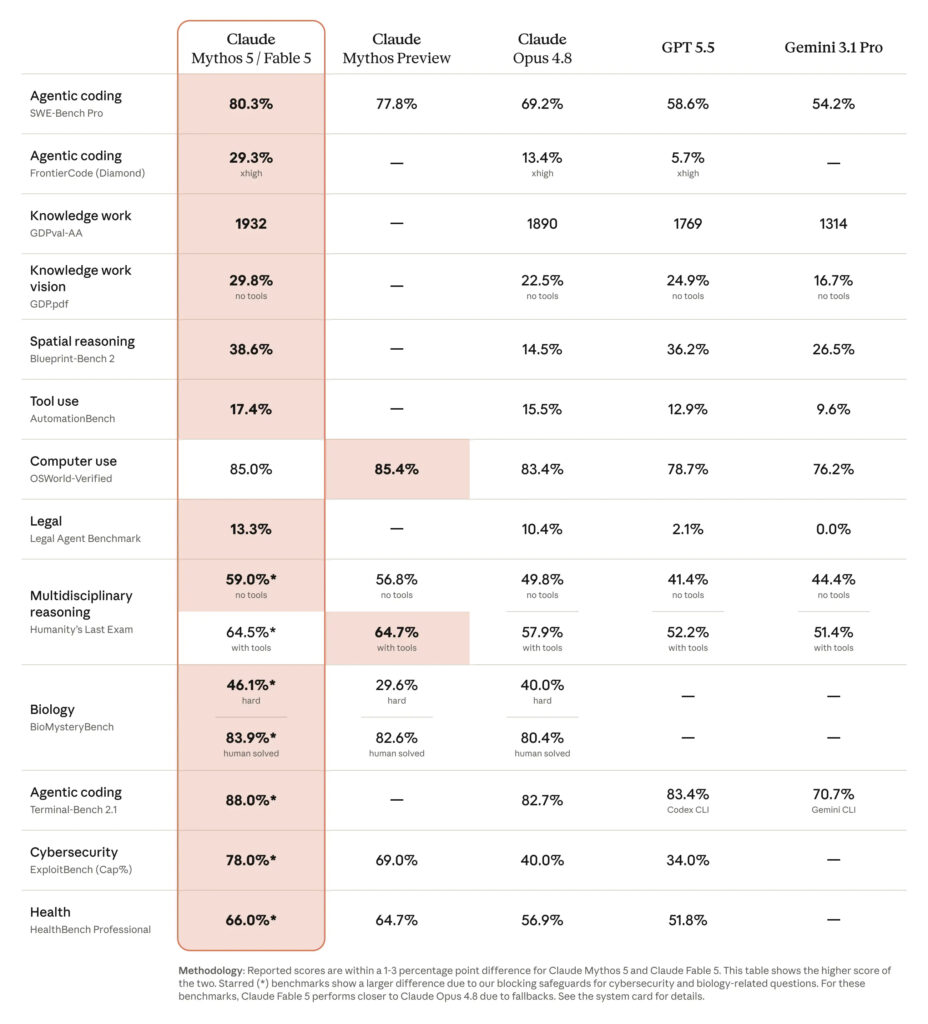
各ベンチマークの概要と進歩
- SWE-Bench Pro(80.3% vs Opus 69.2%): 実在のOSSリポジトリのバグを最初から最後まで自力で修正できるかを測る、エージェント的コーディングの標準指標。+11ポイントは世代差として大きい伸びです。
- FrontierCode Diamond(29.3% vs 13.4%): Cognition社による、高品質な本番コードベースの基準を満たしながら難問を解けるかを測る評価で、Fable 5はmediumエフォートでも首位。Opusの2倍超で、表中で最も顕著な進歩の一つです。 anthropic
- GDPval-AA(1932 vs 1890): Artificial Analysisによる経済的に価値のあるナレッジワーク全般のElo評価。財務分析・文書作成などの実務能力の総合指標です。
- GDP.pdf(29.8% vs 22.5%): 図表やPDFを読み取って行うナレッジワークを、ツールなし(視覚能力のみ)で測るもの。
- BlueprintBench 2・空間推論(38.6% vs 14.5%): 図面等の空間的理解。約2.7倍と、視覚系で最大の跳躍です。
- AutomationBench・ツール使用(17.4% vs 15.5%): 長時間の業務自動化ワークフロー。絶対値が低いのは意図的に難しく作られているためです。
- OSWorld-Verified(85.0%): 実際のOSのGUI操作(コンピュータ使用)。ここはほぼ飽和域で差が小さい。
- Humanity’s Last Exam(59.0%): 全分野の専門家レベル難問集。
- BioMysteryBench / ExploitBench / HealthBench: 生物学研究・サイバー攻撃能力・医療の各専門評価。星印付きで、Fable 5では安全対策によりMythosのスコアより低くなります。
- Terminal-Bench 2.1(88.0%): ターミナル環境での自律的コーディング作業。
従来モデルからFable5が進化したポイント
- エージェント的コーディング(SWE-Bench Pro): 80.3%(Opus 4.8は69.2%)。実在のOSSのバグを自力で修正する能力で、+11ポイントは世代差として大きい。
- FrontierCode Diamond: 29.3%でOpus 4.8(13.4%)の2倍超。本番品質のコードベース基準を満たしながら難問を解く評価で、Fable 5はmediumエフォートでも全モデル中首位とされる[^1]。
- 空間推論(BlueprintBench 2): 38.6%と、Opus 4.8(14.5%)から約2.7倍。図面・図表の読解力の向上は、有価証券報告書や財務諸表のような構造化文書の解析精度に直結する。
- ナレッジワーク(GDPval-AA): Elo 1932で首位。財務分析等の実務能力の総合指標である。
- コンピュータ使用(OSWorld-Verified): 85.0%。この領域はすでに飽和に近く、モデル間の差は小さい。
なお、生物学・サイバーセキュリティ等の星印付き項目はMythos 5のスコアであり、Fable 5の実スコアはセーフガードによるフォールバックの分だけ低くなる点に注意が必要である。
4. Mythos級モデルのFable 5は移転価格対応にも使えるのか?
表中で目を引くのが、法務分野のLegal Agent Benchmark(LAB)の絶対値の低さである。Fable 5が13.3%、Opus 4.8が10.4%、GPT-5.5は2.1%、Gemini 3.1 Proに至っては0.0%。最先端モデルが軒並み「不合格」に見えるこの数字には、構造的な理由がある。
LABはリーガルAI企業Harveyが2026年5月に公開したオープンソースのベンチマークで、24の法律実務分野にわたる1,200超のタスクと、75,000を超える専門家作成のルーブリック基準で構成される[^4]。従来の法務ベンチマークが契約レビューや文書比較といった短時間タスクを測っていたのに対し、LABは「長期にわたる法務業務(long-horizon legal work)」を対象とする点が決定的に異なる[^5]。
具体的には、タスクの指示はパートナー弁護士からアソシエイトへの業務依頼の形式で与えられ、期待される成果物の詳細な説明は付されない。エージェントは案件ファイル、事務所のテンプレート、メール等の文書群というクライアント案件環境の中から必要な情報を自ら発見・選別し、リスク評価やメモといったレビュー可能な成果物を作成しなければならない[^4]。
さらに採点は「all-pass基準」である。事実認定、結論、引用、構成要件、分析手法を規定するルーブリックの全項目を満たして初めて、その1タスクが合格とカウントされる[^6]。つまり13.3%という数字は「部分的に役立った割合」ではなく、「アソシエイト弁護士の成果物として一切の欠落なく完璧だった割合」を意味する。
この設計を踏まえれば、低スコアはモデルの失敗ではなく、ベンチマークが意図的に「現在のAIの限界線」に置かれていることの表れと読むべきである。実際、Fable 5は相対的には全モデル中首位であり、Opus 4.8からの+2.9ポイントは、all-pass基準の厳しさを考えれば実質的な前進である。
実務家にとっての含意は明確だ。移転価格の係争案件一式を渡して反論書を完成稿まで書き切らせる——そうした「丸投げ」はまだ機能しない。一方で、引用照合、数値突合、論点の網羅性チェック、ドラフトの一次生成といった部分タスクでは、すでに人間の作業を大幅に圧縮できる水準にある。AIの役割を「完全代替」ではなく「監督下での部分委任」として設計することが、当面の正解である。
5. 税務・会計実務での使い分け——モデル×エフォートの選択指針
筆者の実務での使い分けの目安を示す。
- 学術論文・意見書の精緻な査読、引用・数値の網羅的突合: Fable 5 / high〜xhigh。検証の徹底度が要であり、一回限りの最終監査ならコストをかける価値がある。
- 比較対象企業選定ツールなど、規制細部をロジックに落とすアプリ開発: Fable 5 / xhigh。仕様の誤実装が後工程に波及するリスクが大きい領域。
- 大量データの集計・分類(G/L分析等): Sonnet 4.6 / high。数百万行はコードで処理させるため、重要なのはコードの正確さでありモデルの「格」ではない。
- 定型文書の整形・翻訳・要約: Sonnet 4.6 / low〜medium。
通底する原則は二つである。「間違えたときの手戻り・実害が大きい仕事ほど、上のモデル×上のエフォート」。そして「量が多くても作業が機械的なら、コードに任せてモデルは下げる」。
おわりに
Fable 5は、AIが「質問に答える道具」から「業務を委任できる存在」へ移行する転換点に位置するモデルである。同時に、LABの13.3%という数字は、法務・税務のような高度専門領域でその実用性がまだ初期の途上段階にあることを正直に示している。実務家に求められるのは、過大評価でも過小評価でもなく、どの部分タスクをどのモデル・どのエフォートで委任するかという「業務設計」の精度である。一方で、LABにおける高難易度な課題の10本に1本はすでにジュニアレベルの専門家と同等のアウトプットを出せているという事実は、その表面的な数字の低さに専門家として持つべき危機感を覆い隠されている気がしてならない。
参考資料
[^1]: Anthropic, “Claude Fable 5 and Claude Mythos 5” (June 9, 2026) — https://www.anthropic.com/news/claude-fable-5-mythos-5
[^2]: Anthropic, “Effort” Claude API Docs — https://platform.claude.com/docs/en/build-with-claude/effort
[^3]: Anthropic, “Prompting Claude Fable 5” Claude API Docs — https://platform.claude.com/docs/en/build-with-claude/prompt-engineering/prompting-claude-fable-5
[^4]: Harvey, “Introducing Harvey’s Legal Agent Benchmark” (May 6, 2026) — https://www.harvey.ai/blog/introducing-harveys-legal-agent-benchmark
[^5]: LawSites, “Some Thoughts On Harvey’s Launch of ‘LAB'” (May 2026) — https://www.lawnext.com/2026/05/some-thoughts-on-harveys-launch-of-lab-an-open-source-long-horizon-benchmark-for-legal-ai-agents.html
[^6]: Harvey, “Legal Agent Benchmark Initial Results” (May 2026) — https://www.harvey.ai/blog/legal-agent-benchmark-initial-results
本稿の記載は公開情報に基づく筆者の整理であり、特定のサービス利用を推奨するものではありません。ベンチマークスコアおよび価格・提供条件は2026年6月10日時点の情報です。